
What is the pyopenms skill? The pyopenms skill packages the OpenMS / pyOpenMS computational mass-spectrometry stack for an AI agent: a SKILL.md plus 16 ready-to-run CLI scripts and 6 reference documents, all targeting pyOpenMS 3.5.0. It is part of K-Dense's open-source Scientific Agent Skills library, and it is the subject of the benchmark below.
If you do mass spectrometry, you already write code. You parse mzML, you tune a feature finder, you align runs, you link consensus features, you filter identifications at a sensible FDR, and you glue it all together with pandas. Increasingly that code is written with an AI coding agent sitting next to you, whether that is Claude Code, Cursor, or a hosted research platform. The promise is obvious: describe the analysis in plain language and let the agent drive pyOpenMS, the Python bindings to OpenMS, end to end.
The catch is that pyOpenMS is a fast-moving library, and the agent's knowledge of it is frozen at its training cutoff. Version 3.5.0 removed and renamed several of the exact APIs that matter most for real proteomics and metabolomics work. A model that learned the old way will confidently write code that either crashes against the new API or, worse, runs cleanly and returns a plausible but wrong answer. So we asked the practical question and answered it with numbers. When you give an agent the pyopenms skill, what do you gain in correctness, how much time and money does it cost, and where exactly does the benefit show up?
To answer it we ran a controlled benchmark: a coding agent solved ten real mass-spectrometry tasks, each five times with the skill and five times without it, on two model tiers, plus a third arm that forces the weaker model to actually use the skill. That is 250 agent runs, and the only thing that changes between the core arms is whether the skill is present.
The pyOpenMS 3.5.0 trap
Before the results, it helps to see why this is hard, because the failure mode is specific and it is not "the model is bad at Python." The model is fine at Python. It is wrong about pyOpenMS 3.5.0, and it is wrong in ways that look right. These are the changed APIs the skill documents explicitly, and they are exactly where agents stumble.
Feature finding was restructured. The old one-liner is gone, and untargeted metabolomics now runs through a three-stage pipeline.
# Pre-3.5.0 code a model tends to write from memory (now broken):
ff = FeatureFinder("centroided") # this constructor was removed
# What actually works in 3.5.0 for metabolomics:
# MassTraceDetection -> ElutionPeakDetection -> FeatureFindingMetabo
# (and FeatureFinderAlgorithmPicked for centroided proteomics data)
idXML writing needs a typed list. Handing the writer a plain Python list of peptide identifications raises the cryptic can not handle type error, which sends agents into a long, expensive debugging loop.
# Plain list -> "can not handle type"
IdXMLFile().store("out.idXML", protein_ids, peptide_ids) # peptide_ids = [...]
# 3.5.0 wants a PeptideIdentificationList (protein IDs stay a plain list):
peptide_ids = PeptideIdentificationList()
Adduct grouping uses a non-obvious syntax. The class is MetaboliteFeatureDeconvolution, and it does not accept the bracket notation ([M+H]+) that everyone writes by hand. It wants Elements:Charge:Probability triples, and getting this wrong is how a run annotates zero adducts without ever raising an error.
# Bracket notation silently yields no adducts.
# 3.5.0 expects Elements:Charge:Probability:
p.setValue("potential_adducts", [b"H:+:0.4", b"Na:+:0.2", b"H-2O-1:0:0.05"])
There are quieter traps too, like FeatureMap.get_df() returning lowercase rt/mz columns (not RT), and ConsensusMap exposing get_intensity_df() and get_metadata_df() for the quant table. Each one is a small thing. Together they are the difference between a pipeline that runs first try and one that flails for twenty turns or, worst of all, ships a clean-looking but noise-laden result.
How the benchmark works
We compare two arms that are identical except for one variable. In the with_skill arm the agent's working directory contains the skill at .claude/skills/pyopenms, so it is discoverable and usable; in the without_skill arm the directory is empty and the agent relies on its own knowledge. Everything else is held constant: same model, same prompt, same tool permissions, same pre-installed Python environment, same input data, same isolated filesystem.
Each run is a headless Claude Code agent, invoked non-interactively with a fixed allow-list of tools so it can autonomously write and run Python, read files, and (when present) invoke the skill, with no human in the loop.
claude -p "<task prompt>" \
--output-format stream-json --verbose \
--model <model> \
--setting-sources project \
--allowedTools "Bash Read Write Edit Skill Glob Grep" \
--add-dir <data_dir>
A few design choices are worth calling out, because they make the test conservative rather than flattering:
- The environment is pre-installed for both arms. A Python 3.13 venv with pyOpenMS 3.5.0, pandas, numpy, and matplotlib is provided to every run. This deliberately removes "can the agent install the package?" as a confound, so what we measure is pure API and workflow knowledge, not setup luck.
- Ground truth is isolated. The expected answers and the grader live outside any directory the agent can read. The agent only gets read access to the input data.
- Grading is fully automated and objective. There is no LLM-as-judge. A script checks each run's
answer.jsonand output files against ground truth that was computed directly from the pyOpenMS API, independent of the skill's own scripts.
The ten tasks span the common MS analysis surface, from textbook chemistry to multi-step LC-MS/MS pipelines. All inputs are real, public data: two LC-MS metabolomics runs from the pyOpenMS tutorial dataset, a peptide identification result from the OpenMS test suite, and the canonical human ubiquitin sequence (UniProt P0CG48).
| # | Task | Category | Tier | What the agent must produce |
|---|---|---|---|---|
| 1 | peptide_mass |
Chemistry | 1 | Monoisotopic mass plus [M+2H]²⁺/[M+3H]³⁺ m/z of a modified peptide (oxidized Met) |
| 2 | tryptic_digest |
Chemistry | 1 | In-silico tryptic digest of ubiquitin (up to 2 missed cleavages); count peptides and those in 800-2500 Da |
| 3 | theoretical_spectrum |
Chemistry | 1 | y3 and b2 fragment-ion m/z for peptide PEPTIDE |
| 4 | isotope_pattern |
Chemistry | 1 | Monoisotopic mass plus relative M+1 isotope intensity of C₆H₁₂O₆ |
| 5 | inspect_mzml |
Inspection | 1 | MS1/MS2 counts and m/z range of a real LC-MS/MS file |
| 6 | detect_features_metabo |
Feature detection | 2 | Untargeted metabolomics feature detection on a real sample |
| 7 | detect_adducts |
Annotation | 2 | Detect features, then group adducts and charge variants |
| 8 | multisample_quant |
Quantification | 2 | Two-sample label-free quant: detect, align, link, export matrix |
| 9 | idxml_filter |
Identification | 1 | Filter peptide search results to the best hit per spectrum; write idXML |
| 10 | convert_mgf |
File conversion | 1 | Convert mzML to MGF, exporting MS2 spectra |
We grade in two tiers. Tier 1 tasks (the chemistry, inspection, identification, and conversion tasks) have unambiguous numeric answers checked within tight tolerances, and for file-producing tasks we re-load the output to confirm it is structurally correct. Tier 2 tasks (feature detection, adducts, quantification) are different, because feature counts are strongly parameter-dependent: with raw library defaults the same file yields roughly 8,600 noise-laden traces, while sensible LC-MS parameters yield about 390 clean features, a 22-fold difference. Since both are "valid code," we do not grade Tier 2 on an exact count. A Tier 2 task passes only if the agent runs the pipeline without crashing, produces a correctly structured output, and returns a non-degenerate result. This isolates the dominant failure mode, crashing on changed APIs, from legitimate parameter variation.
Finally, the replication. Each task and arm combination is run five times. The full ten-task suite runs on two model tiers, Claude Sonnet 4.6 (strong) and Claude Haiku 4.5 (small and cheap), and on Haiku we add a third skill-forced arm whose prompt requires the agent to invoke the skill. That third arm matters more than it sounds, and we will come back to why. The full design and caveats are documented alongside the raw transcripts in the benchmark repository.
Finding 1: on a strong model, the skill makes the agent more correct and cheaper
Start with the conservative case. Sonnet already knows a fair amount of pyOpenMS and often recovers from its own mistakes, so it is the hardest model to improve. Even here, the skill helps on every axis at once.

| Metric | Without skill | With skill | Change |
|---|---|---|---|
| Success rate | 96% (48/50) | 100% (50/50) | zero failures |
| pyOpenMS-API errors / run | 1.00 | 0.08 | -92% |
| Wall-clock time / task | 42.3 s | 33.8 s | -20% |
| Total tokens / task | 197.8k | 173.7k | -12% |
| Output tokens / task | 2,293 | 1,459 | -36% |
| Cost / correct result | $0.180 | $0.162 | -10% |
| Skill adoption | n/a | 98% | n/a |
The mechanism here is simple. A capable model that hits a changed API can usually claw its way back, but it does so expensively, burning turns and tokens on a debugging loop. The skill removes the loop by getting the API right the first time, which is why pyOpenMS-API errors fall by roughly twelve-fold (1.00 to 0.08 per run) and output tokens, the most expensive component, drop by more than a third.
That average hides a sharper story, though, and splitting routine tasks from the version-specific pipeline tasks is the most useful view in the whole study.
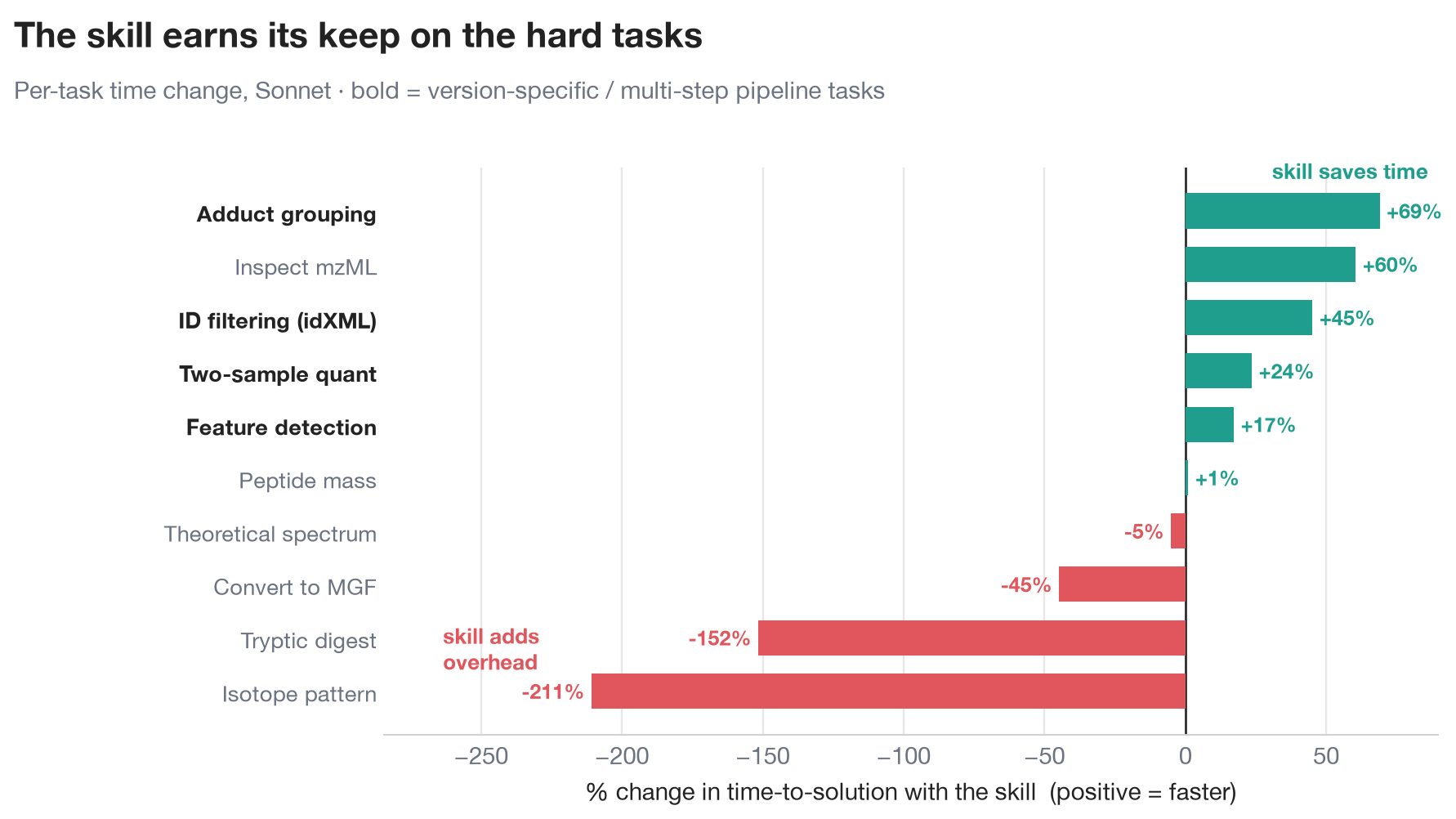
| Task group | Arm | Success | Time | Tokens | Cost | API err/run |
|---|---|---|---|---|---|---|
| Version-specific / pipeline (n=20) | Without | 95% | 69 s | 293k | $0.237 | 2.35 |
| With | 100% | 36 s | 196k | $0.180 | 0.10 | |
| Routine (n=30) | Without | 97% | 24 s | 134k | $0.130 | 0.10 |
| With | 100% | 32 s | 159k | $0.151 | 0.07 |
On the hard tasks, the ones that hit the 3.5.0 API changes, the skill is about twice as fast, 24% cheaper, and produces roughly 23 times fewer API errors. Adduct grouping alone goes from 123 seconds to 38, and ID filtering from 68 seconds to 37. On the routine tasks (peptide mass, a tryptic digest, a file conversion) a strong model is already fine on its own, so the skill is a mild overhead. That is the honest flip side, and it is small. Across a realistic mixed workload the skill wins comfortably, because the expensive pipeline tasks dominate the bill.
Finding 2: on a weak model, the skill is transformative, but only when it is actually used
The strong-model result is encouraging. The weak-model result is the one that should change how you work. Haiku is small, cheap, and a much closer stand-in for the budget-conscious, high-throughput agent many labs would actually deploy at scale.
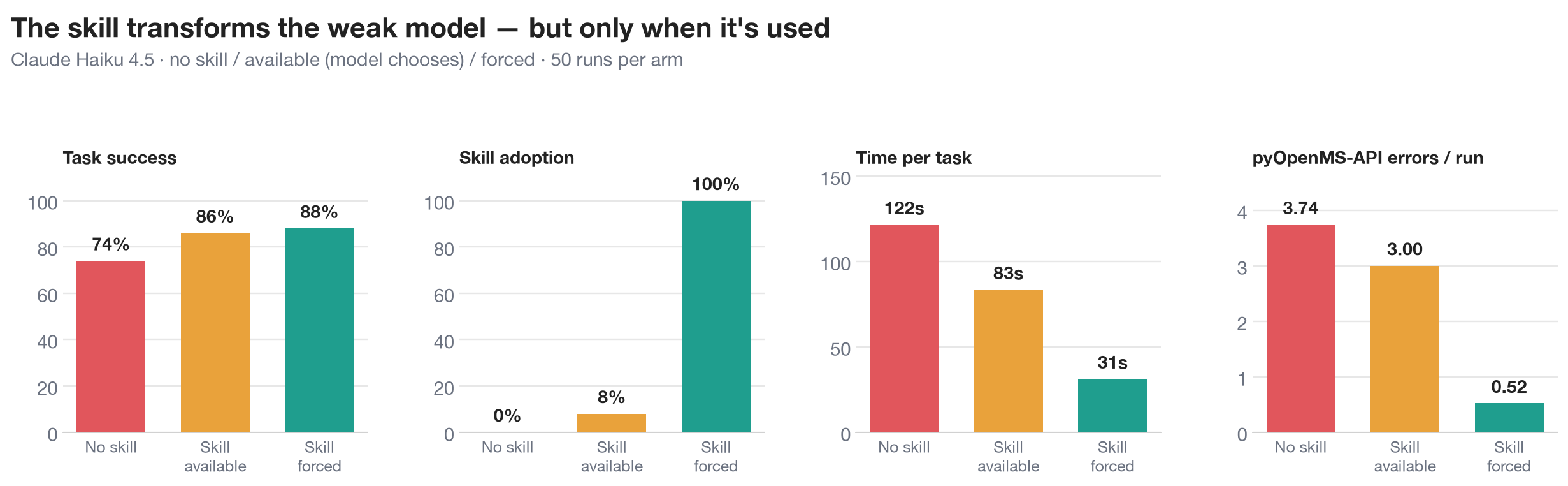
| Metric | No skill | Skill available (auto) | Skill forced |
|---|---|---|---|
| Success rate | 74% | 86% | 88% |
| Skill adoption | 0% | 8% | 100% |
| Wall-clock time / task | 121.5 s | 83.5 s | 31.1 s |
| Total tokens / task | 656k | 606k | 264k |
| Cost / task | $0.152* | $0.133* | $0.074 |
| pyOpenMS-API errors / run | 3.74 | 3.00 | 0.52 |
| Agent turns / task | 17.1 | 16.2 | 8.7 |
| Runs that hit the 10-min timeout | 3 | 1 | 0 |
* Haiku's no-skill and auto cost and token means exclude four runs that hit the 600 s timeout and emitted no usage telemetry, so those two columns are conservative and the true cost is higher.
Without the skill, Haiku flails. It averages two minutes per task, 656k tokens, 17 turns, nearly four pyOpenMS-API errors per run, and it times out entirely on the hardest tasks. That is roughly three times slower and three times more token-hungry than Sonnet, for a 74% success rate. The skill's content is exactly what would rescue it, and yet making the skill merely available barely helps, because Haiku reaches for it in only 8% of runs. The instructions are sitting right there in the working directory, and the small model mostly does not invoke them. (Sonnet, by contrast, invoked the skill 98% of the time.)
Forcing the skill changes everything. With a one-line instruction to invoke pyopenms before solving the task, adoption goes to 100% and Haiku lands at 88% success in 31 seconds at $0.074 per task. That is about four times faster, 60% fewer tokens, 51% cheaper, roughly seven times fewer API errors, and zero timeouts, all relative to the same model with no skill. At that point the cheap model is both faster and less than half the cost of the strong one.
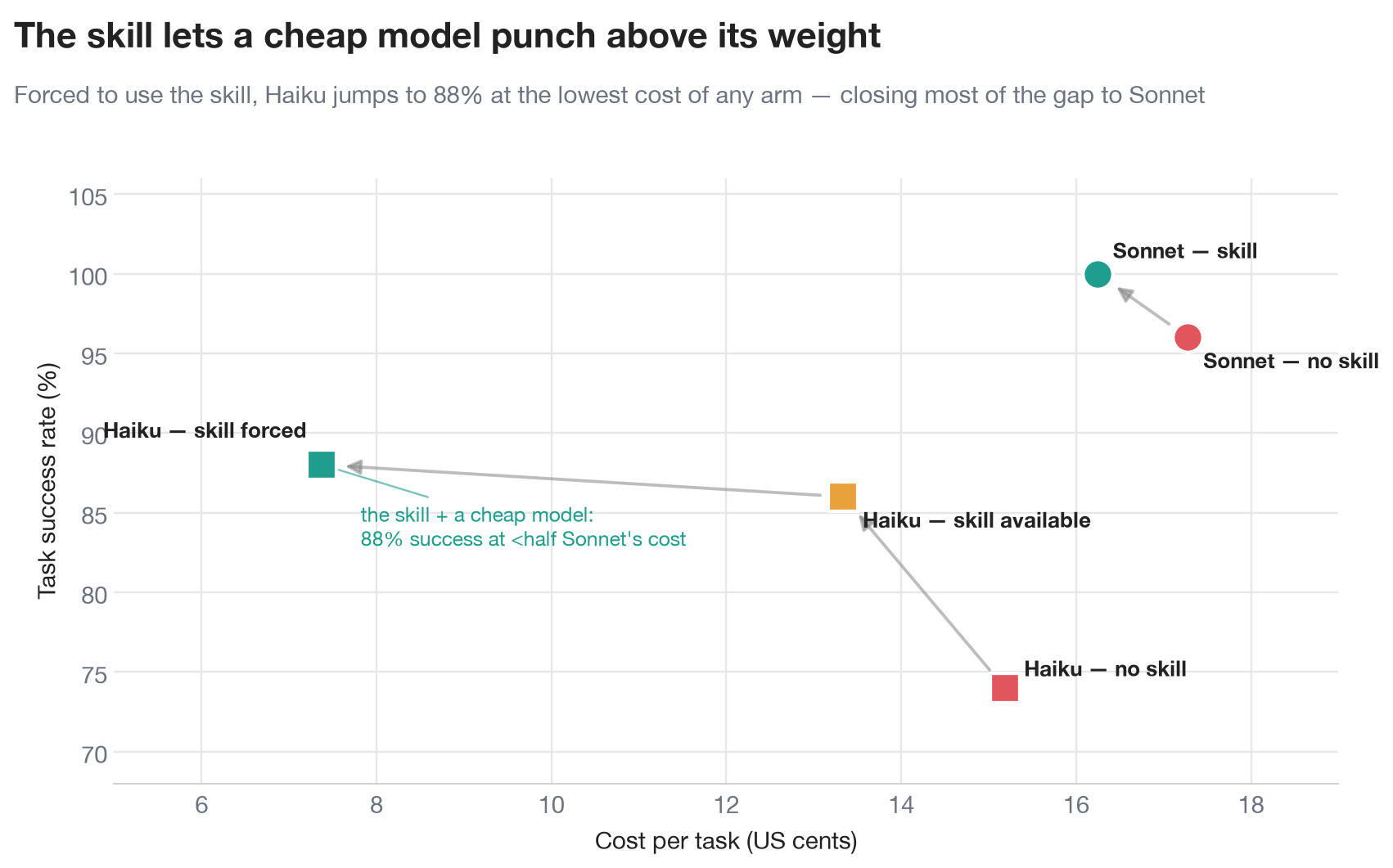
The frontier chart makes the punchline visual. Forced Haiku sits at the bottom-left, the cheapest arm in the entire study, while still reaching 88% success and closing most of the accuracy gap to Sonnet. The takeaway for anyone deploying agents is concrete and a little counterintuitive: a great skill is necessary but not sufficient, because a weak model has to actually trigger it. For smaller or cheaper models, do not rely on auto-trigger. Invoke the skill explicitly, with a slash command like /pyopenms or a direct instruction to "use the pyopenms skill," and you convert a flailing agent into a fast, reliable, and cheap one.
Finding 3: the skill prevents silent, plausible-looking wrong science
A crash is annoying but honest; you know something failed. The failures that should worry a working scientist are the ones that return a clean number that happens to be wrong. The skill's biggest contribution may be that it prevents those.
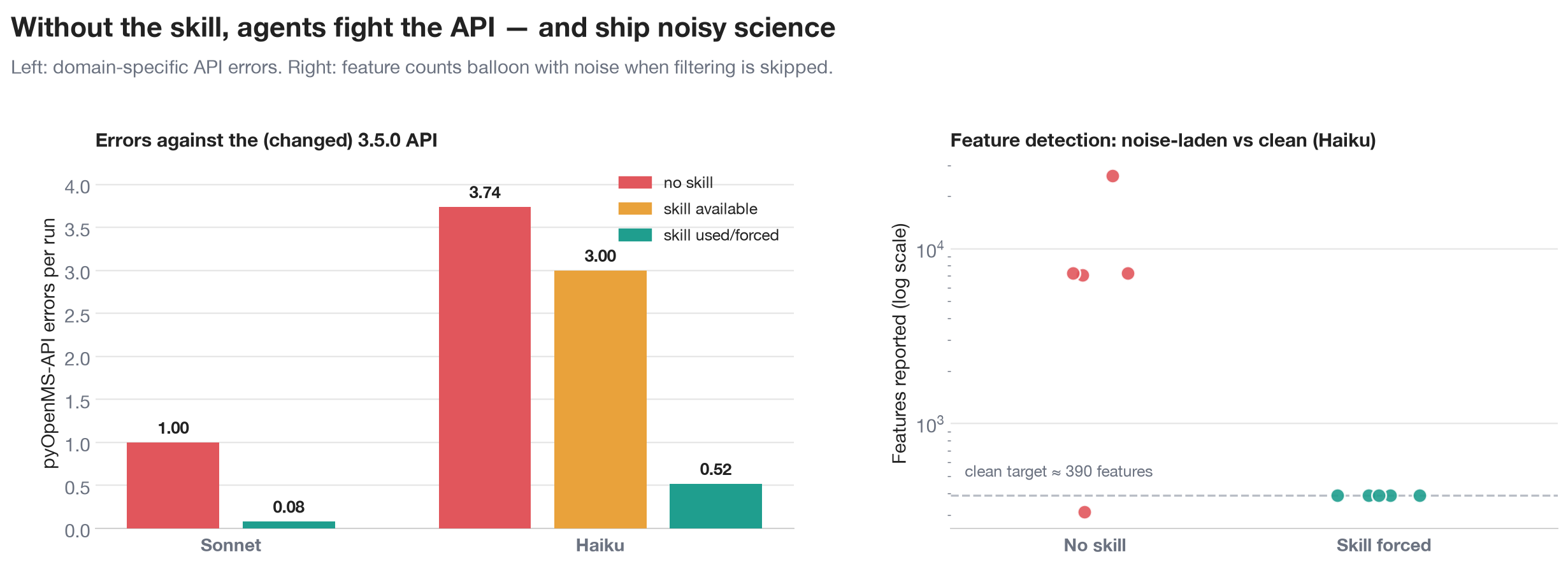
First, the error reduction is specific to pyOpenMS, not generic Python. Splitting the error events on Sonnet, the pyOpenMS-API errors drop from 1.00 to 0.08 per run with the skill, while generic errors (a missing file, a script accidentally shadowing a standard-library module) stay roughly flat at about 0.38 to 0.34. The skill fixes domain and version mistakes, which is exactly what you would want it to fix and nothing it should not.
Second, and more important, are the two silent failure modes we caught in the no-skill Sonnet runs. On peptide_mass, a run computed the neutral monoisotopic mass correctly but returned the wrong charged m/z, reporting an [M+2H]²⁺ of 574.26 instead of 583.27. It is a plausible number, and in a real workflow it would propagate downstream undetected. On detect_adducts, a run completed without error but annotated zero adducts, because it mis-used the 3.5.0 MetaboliteFeatureDeconvolution syntax. The code "ran." The science was empty.
Third is result quality on the feature-detection tasks, which the pass/fail grader deliberately ignores. Recall that raw defaults yield about 8,600 noise-laden traces against roughly 390 clean features. We flag a result as "noise-inflated" when its count exceeds four times the clean reference, and the pattern is stark.
| Noise-inflated feature lists | No skill | Skill available | Skill forced |
|---|---|---|---|
| Sonnet | 1/15 | 0/15 | n/a |
| Haiku | 13/15 | 10/15 | 0/15 |
The strong model rarely over-counts, because it sets sensible parameters on its own. The weak model produces noise-laden feature lists almost every time without the skill (13 of 15 runs), and forcing the skill eliminates the problem entirely (0 of 15). Merely making the skill available does not fix it, again because Haiku usually does not invoke it. If you have ever inherited a feature table with thousands of phantom peaks, you know this is the difference between a usable result and a week of cleanup.
Per-task detail (Sonnet)
For completeness, here is the full per-task breakdown on Sonnet, with success out of five per arm and the rest as per-run means. The two bold rows are the worst API-trap offenders, and they are exactly where the skill earns its keep.
| Task | Tier | Success wo to wi | API err wo to wi | Time wo to wi | Tokens(k) wo to wi | Cost wo to wi |
|---|---|---|---|---|---|---|
| peptide_mass | 1 | 4/5 to 5/5 | 0.0 to 0.0 | 24 to 24 s | 125 to 111 | $0.138 to $0.125 |
| tryptic_digest | 1 | 5/5 to 5/5 | 0.0 to 0.0 | 16 to 40 s | 81 to 212 | $0.100 to $0.187 |
| theoretical_spectrum | 1 | 5/5 to 5/5 | 0.0 to 0.0 | 23 to 24 s | 119 to 158 | $0.119 to $0.143 |
| isotope_pattern | 1 | 5/5 to 5/5 | 0.4 to 0.4 | 22 to 67 s | 131 to 202 | $0.121 to $0.183 |
| inspect_mzml | 1 | 5/5 to 5/5 | 0.2 to 0.0 | 47 to 18 s | 268 to 119 | $0.204 to $0.128 |
| detect_features_metabo | 2 | 5/5 to 5/5 | 0.4 to 0.0 | 32 to 26 s | 139 to 154 | $0.136 to $0.148 |
| detect_adducts | 2 | 4/5 to 5/5 | 4.2 to 0.0 | 123 to 38 s | 464 to 212 | $0.363 to $0.196 |
| multisample_quant | 2 | 5/5 to 5/5 | 0.0 to 0.0 | 54 to 41 s | 150 to 220 | $0.173 to $0.188 |
| idxml_filter | 1 | 5/5 to 5/5 | 4.8 to 0.4 | 68 to 37 s | 420 to 196 | $0.275 to $0.187 |
| convert_mgf | 1 | 5/5 to 5/5 | 0.0 to 0.0 | 15 to 21 s | 81 to 152 | $0.098 to $0.140 |
Should you use this?
If your work is real proteomics or metabolomics pipelines, the answer is yes. Feature detection, adduct annotation, label-free quantification, and identification filtering are precisely where agents stumble on pyOpenMS 3.5.0, and they are precisely where the skill turns flailing into first-try success, roughly twice as fast and about a quarter cheaper on the hard tasks, with API errors essentially gone. Just as importantly, the skill prevents the silent, plausible-looking mistakes (a wrong charged m/z, an empty adduct annotation, a noise-laden feature list) that are scientifically worse than an honest crash because they do not announce themselves.
The skill also lets a cheap model punch well above its weight. Haiku using the skill reached 88% success, up from 74%, at half the cost and equal speed to a frontier model. The crucial caveat is that you must make a smaller model actually invoke the skill, with an explicit /pyopenms or a direct instruction, rather than trusting auto-trigger. For one-off trivial calculations a strong model is already fine and the skill is light overhead, so its value concentrates exactly where the work is non-trivial, which is to say where you spend most of your time.
Two honest caveats keep this grounded. We pre-installed pyOpenMS for both arms, which removes a real-world hurdle the skill would otherwise clear (discovering and installing the right version), so the benchmark understates the everyday benefit. And the Tier 2 grader checks valid execution and a broad plausibility band rather than parameter optimality, which again makes the estimate conservative. Both point the same direction: in practice, the skill is worth more than these numbers show.
The broader point is the one we keep coming back to. The bottleneck in computational science is no longer raw model intelligence; it is the gap between a capable general model and the specific, version-correct procedural knowledge a domain requires. A small, auditable, version-pinned skill closes that gap, and the data here shows it does so measurably. If you are an MS scientist who has been skeptical of letting an agent touch your pipelines, this is the missing piece. Pair a good agent with the pyopenms skill, point it at your data, and spend your time on the science instead of on the API.
Questions, or a skill you want benchmarked? Email contact@k-dense.ai.